

Hearsay
 If you were asked to give a description of the painting above, you might first mention the subject matter – the boat, the man, the birds, the location, etc. Then you might describe the range of colours in the picture and their brightness. Or the picture’s composition, the balance of detail versus blocks of colour. Or the shapes and angles, the verticality or horizontality, the use of lines and curves.
If you were asked to give a description of the painting above, you might first mention the subject matter – the boat, the man, the birds, the location, etc. Then you might describe the range of colours in the picture and their brightness. Or the picture’s composition, the balance of detail versus blocks of colour. Or the shapes and angles, the verticality or horizontality, the use of lines and curves.
You probably wouldn’t begin by asking yourself if it was painted right-handed or left-handed. Or if the artist held the brush between thumb and extended index finger, like a pen, or with the hand in a fist shape, with the thumb on top. Or whether the artist’s fingers or wrist were more active, or the whole arm.
Phonetics, for a lot of people, is mainly about questions like those in the second paragraph: less about describing speech sounds than about describing body movements which may have produced them. So “sounds” are depicted with cross-sectional diagrams of the head, or as lip and tongue movements, or by means of a phonetic alphabet each of whose letters is intended as an abbreviation for an articulatory description.
Of course the body movements involved in speaking are a valid and intriguing object of study, like the body movements involved in painting, or in drawing, or in writing. But I don’t think they should be the main, still less the sole, focus of attention in phonetics.
 I didn’t really become aware of this until the mid-late 1980s, when I was working on a speech technology project at UCL under Adrian Fourcin. It was through invaluable discussions with Adrian – now Emeritus Professor of Experimental Phonetics – that I grasped the prime importance of perceptible “speech patterns” and the fundamental asymmetry between the auditory-acoustic and the articulatory branches of phonetics.
I didn’t really become aware of this until the mid-late 1980s, when I was working on a speech technology project at UCL under Adrian Fourcin. It was through invaluable discussions with Adrian – now Emeritus Professor of Experimental Phonetics – that I grasped the prime importance of perceptible “speech patterns” and the fundamental asymmetry between the auditory-acoustic and the articulatory branches of phonetics.
It’s obvious that we don’t learn to write before we learn to read: we learn the visual patterns first, then how to produce them. But in phonetics the articulatory bias is so widespread that it’s worth pointing out that the same is true of speech. In language acquisition, perception seems broadly to precede production: we learn to articulate in order to produce the auditory-acoustic speech patterns which we have already heard and stored in our mind’s ear.
This is why the prelingually deaf generally don’t acquire normal speech articulation, while normal speech perception is possible for those with motor deficits. It’s obvious that normal speaker-hearers can perceive speech correctly without simultaneously speaking, but crucially we’re not able to speak correctly without simultaneously hearing: the speech of those who lose their hearing rapidly suffers, and most of us have noticed how headphone-wearers instantly and unwittingly raise their voices – because auditory guidance is so crucial for good articulation.
The great phonetician David Abercrombie declared that “Speech may be said to consist of movements made audible” – a classic statement of the articulatory view. But this makes speech a sub-field of kinesiology, and draws attention away from the central fact that speech sounds are communicative signs. The primary object of study, it seems to me, is the signs rather than whatever movements produced them (although of course the movements have great interest in their own right).
Overall, my time on that speech technology project was rather dispiriting. My end of things, phonetics and phonology, seemed to have disappointingly little to contribute to the synthesis and recognition of communicative signs – Adrian’s speech patterns. Phonetics and phonology were skewed towards articulatory descriptions; indeed, they seemed to be becoming more articulatory than ever, the latest trends back then including “feature geometry” and “articulatory phonology”.
If speech synthesis had focused on building artificial mouths rather than generating audible speech patterns, it would probably still be stuck at the stage of flying machines with flapping wings; Stephen Hawking and others may well have been doomed to silence. Nonetheless, robot articulators (like ornithopters) are fascinating and good fun to watch.
Likewise, artificial speech recognizers – the sort of thing used to provide captioning for the deaf when transcription by humans is impractical – would be non-starters if they required inserting a battery of movement-sensors into the speaker’s vocal tract, or needed the speaker to lie in an MRI scanner.
Of course, technology – or rather lack of it – is one of the main reasons for articulatory bias. Today virtually everyone owns a mobile device for receiving and transmitting auditory-acoustic speech patterns, and the digital revolution has made the recording and analysis of sound signals cheap, quick and easy. But the great early pioneers of phonetics simply had no ready means to analyze sound. As recently (!) as my own student days, spectrographic analysis required cumbersome, expensive equipment that took minutes to analyze just a couple of seconds of speech, all the while producing noxious smoke as it burned the acoustic image onto special paper. Auditory-acoustic analysis was the preserve of a few well-funded labs. It was an optional extra for the later chapters of phonetic textbooks, something to be covered in second-level courses to which the majority of students never progressed. The first-level courses dealt with head diagrams, tongue spaces, etc., and there arose, I think, a myth of relative articulatory simplicity: a notion that articulation is reassuringly well understood and easy to grasp, while auditory-acoustic phonetics dauntingly involves labs, white coats and maths.
Auditory-acoustic analysis was the preserve of a few well-funded labs. It was an optional extra for the later chapters of phonetic textbooks, something to be covered in second-level courses to which the majority of students never progressed. The first-level courses dealt with head diagrams, tongue spaces, etc., and there arose, I think, a myth of relative articulatory simplicity: a notion that articulation is reassuringly well understood and easy to grasp, while auditory-acoustic phonetics dauntingly involves labs, white coats and maths.
The problem with this myth is that it doesn’t compare like with like. The myth equates “articulatory phonetics” with the classification of speech sounds into linguistically relevant categories, e.g. “bilabial”, “voiced”, “rounded”; and it equates “acoustic phonetics” with instrumental measurement and quantification. This is a blunder on both counts.
Measurement is just as important in articulatory phonetics as it is in acoustic phonetics. For years now, the latter has been far easier, but real articulatory work has always been challenging. Early phoneticians did their best. Daniel Jones’s Outline of English Phonetics (1919), for example, took the measurement of articulation very seriously. Jones recommended devices like “Atkinson’s Mouth Measurer” and “Zünd-Burguet’s Quadrant Indicator”, the latter using rubber “exploratory bulbs” held on the tongue:
 The Quadrant Indicator highlights several of the drawbacks that articulatory techniques have tended to suffer from. One is invasiveness: interference with the very articulation that is being studied. Another is the necessary presence of the speaker: we can analyze the acoustics of speech recorded a century ago, or of an abusive phone caller whose identity is unknown; but the articulations in question are completely inaccessible.
The Quadrant Indicator highlights several of the drawbacks that articulatory techniques have tended to suffer from. One is invasiveness: interference with the very articulation that is being studied. Another is the necessary presence of the speaker: we can analyze the acoustics of speech recorded a century ago, or of an abusive phone caller whose identity is unknown; but the articulations in question are completely inaccessible.
Another drawback is staticness: many articulatory techniques deal best with steady-states, which is completely at odds with the fundamental fact that articulation is movement (though it dovetails reassuringly with the naivety of discrete written symbols).
A further potential problem is that of health risks, which may be more serious than gagging on a rubber bulb. Concerns about radiation dosages put an end to the invaluable source of non-static articulatory data which was provided by x-ray movies. And yet another drawback suffered by many articulatory techniques is expense: while state-of-the-art acoustic analysis can now be done for free by anyone who can download software, a used MRI scanner might set you back $100,000 or more.
As Ladefoged says in Vowels and Consonants:
For many years we have been gathering information about the acoustics of speech… This constitutes far and away the greatest amount of data on the languages of the world available today. There is also, to be sure, a great deal of ongoing research into the articulation of speech – precise measurements of the positions of the tongue, lips and other articulators by means of magnetic resonance imaging, ultrasound, and other biomedical imaging techniques. But… the range of languages for which there is a substantial body of such data is still very limited…
Nor does the classification of speech sounds into linguistically-relevant categories have to be done on articulatory grounds, though this is the assumption expressed in the Principles of the IPA:
The IPA is intended to be a set of symbols for representing all the possible sounds of the world’s languages. The representation of these sounds [sic] uses a set of phonetic categories which describe how each sound is made [sic].
It’s understandable that linguistically-relevant categories were given articulatory labels by “pre-acoustic” phoneticians. But it’s at least as important – arguably more so – to characterize these categories in terms of the auditory-acoustic patterns that we detect when listening to speech and which are the reference targets we aim to reproduce when we speak.
The familiar articulatory labels can be misleading, not only because they reinforce the misconception of phonetics as essentially kinesiology, but also because they’re so often simplistic or inaccurate. My previous post, for example, tried to provide some acoustic substance to replace the simplistic and inaccurate articulatory view of vowels which is absorbed by successive generations of phonetics students and which continues to be encouraged by the IPA.
Consonants, too, are widely considered to “be” the articulatory gestures which produce them. But a given speech pattern can generally be produced by a range of articulatory gestures. A particularly vivid example of this is the radically differing articulations which can be employed to produce the auditory-acoustic pattern of r-colouration: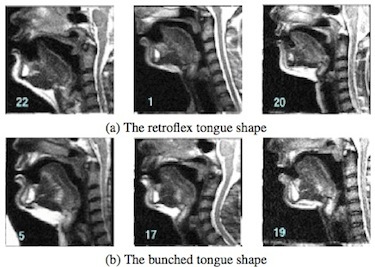 The question whether a given “r” was articulated with the tongue curled or bunched is not unlike the question whether a painting was done left-handed or right-handed: it’s not uninteresting, it may be detectable, it may even be of “forensic” relevance, but the distinction is not essential to what’s being signalled.
The question whether a given “r” was articulated with the tongue curled or bunched is not unlike the question whether a painting was done left-handed or right-handed: it’s not uninteresting, it may be detectable, it may even be of “forensic” relevance, but the distinction is not essential to what’s being signalled.
Or consider the “bilabial” sounds here in Most of the time I have a clear picture:
which aren’t really bilabials because the speaker is Freddie Mercury. Even without Freddie’s famously prominent upper front teeth, “bilabials” are often made labiodentally, particularly when speakers smile: here soprano Renée Fleming greets her fellow-diva “Debbie” Voigt with a grinning “b” that’s even less bilabial then Freddie’s “m” in time:
 Nor does a broad smile convert so-called “rounded” vowels into their “unrounded” counterparts. When we smile, as when we talk with a pen between our teeth, we adjust our articulations, keeping our speech sounds as close as possible to their auditory-acoustic targets. Likewise, the category “voiced” doesn’t equate to the vibration of the vocal cords. Languages don’t lose their so-called “voiced/voiceless” distinctions when speakers whisper. The auditory-acoustic patterns which embody these distinctions include characteristics of intensity, duration and spectral balance which survive in whisper.
Nor does a broad smile convert so-called “rounded” vowels into their “unrounded” counterparts. When we smile, as when we talk with a pen between our teeth, we adjust our articulations, keeping our speech sounds as close as possible to their auditory-acoustic targets. Likewise, the category “voiced” doesn’t equate to the vibration of the vocal cords. Languages don’t lose their so-called “voiced/voiceless” distinctions when speakers whisper. The auditory-acoustic patterns which embody these distinctions include characteristics of intensity, duration and spectral balance which survive in whisper.
Like everyone else, I use terms such as “bilabial”, “rounded” and “voiced”. But as labels for phonological categories, these traditional articulatory names shouldn’t be taken too literally. From the phonetic point of view, they’re not the whole truth and often not the truth at all. Ventriloquists, of course, make a living by producing intelligible speech with scant regard for the IPA rulebook on “how each sound is made”.
(A less publicized tradition exists which gives acoustic definitions to phonological categories. The foremost example is probably Roman Jakobson’s work with Gunnar Fant and with Morris Halle. Sadly, Halle reverted to articulatory bias for his mega-influential collaboration with Chomsky, The Sound Pattern of English. More recent work by myself, John Harris and others has attempted to revive the idea of phonological objects as audible signs.)
Technological history is probably not the only reason for articulatory bias. I suspect that a key factor is the relative importance of our senses, in particular the dominance of vision over hearing. It’s said that between a quarter and a third of neurons in the brain’s cortex are devoted to visual processing, compared with less than ten percent for touch, and only about two percent for hearing.
 Metaphorically, understanding is widely equated with vision. We say “I see” or “I’ve got the picture” to mean that we understand. “Seeing is believing”, the phrase goes, while mere “hearsay” is unreliable. Out of sight, out of mind.
Metaphorically, understanding is widely equated with vision. We say “I see” or “I’ve got the picture” to mean that we understand. “Seeing is believing”, the phrase goes, while mere “hearsay” is unreliable. Out of sight, out of mind.
Recording our visual impressions dates back tens of millennia to cave paintings and the like, but the first recording of any kind of auditory impression was much more recent. The first writing systems represented words as concepts rather than the way they sounded.
When the first phoneticians tried to describe language in its specifically audible form, they unsurprisingly fell back on what they could see; the invisible resonances of the vowels, for instance, were represented as positions of the visible tongue. Note that the IPA does not use articulatory labels for its suprasegmentals section: if early phoneticians been able to get a better view of vocal fold articulation, we might now be referring not to high, low, rising and falling tones, but to stiff, slack, stiffening and slackening tones. (Halle and Ken Stevens proposed such terms as phonological features in the early 1970s.) After all, “stiff tone” and “slack tone” are no more silly as labels than “front vowel” and “back vowel”.
A special case of visual bias is the according of higher status to written language over audible speech. This is even found when the writing in question is phonetic transcription. Occasionally I encounter what I call “paper phoneticians”, people who’ve learned to transliterate from normal English orthography to RP phoneme-letters without acquiring the ability to perceive or produce the relevant contrasts. They’ve learned to rewrite shell and shall as /ʃel/ and /ʃæl/ but they can’t hear the difference between the two words.
In one of the recent posts on John Wells’s magisterial (and sadly discontinued) blog, the normally unflappable John was driven to bold italics by a question from a keen follower as to who among various published transcribers should be considered right:
All of us are “right”. Instead of quoting authorities, why don’t you just listen?
I sympathize with both John and his questioner. 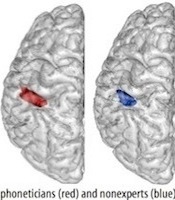 Neuroscientists have presented evidence suggesting that the likes of John and me may be born with freakishly overdeveloped auditory cortices. For the general population, on the other hand, hearing phonetic distinctions is probably not so easy. In Abercrombie’s words, “their remarkable aptitude for copying speech sounds… has left most people not long after they have entered their teens. Certainly, fully-grown adults must be prepared to devote a great deal of labour and time to acquiring the pronunciation of a foreign language”.
Neuroscientists have presented evidence suggesting that the likes of John and me may be born with freakishly overdeveloped auditory cortices. For the general population, on the other hand, hearing phonetic distinctions is probably not so easy. In Abercrombie’s words, “their remarkable aptitude for copying speech sounds… has left most people not long after they have entered their teens. Certainly, fully-grown adults must be prepared to devote a great deal of labour and time to acquiring the pronunciation of a foreign language”.
Prospective pronunciation students sometimes tell me that what they’re after is instruction on how to use their muscles; I’ve yet to have anyone ask for their ear to be trained – which is generally the more basic necessity. Of course I do make use of visual and and proprioceptive techniques.  And there are linguistic contrasts which can be taught ‘articulation first’, e.g. making tooth-lip contact in v but not w, and alveolar contact in l but not ɹ. But such sounds are made with the lips and tongue-tip, the articulators most visible and most innervated by touch receptors. And language learners need to hear contrasts as well as make them. I’ve made ear-training tutorials and quizzes on vowels and tones precisely because these are the two major areas where vision and proprioception are of least use.
And there are linguistic contrasts which can be taught ‘articulation first’, e.g. making tooth-lip contact in v but not w, and alveolar contact in l but not ɹ. But such sounds are made with the lips and tongue-tip, the articulators most visible and most innervated by touch receptors. And language learners need to hear contrasts as well as make them. I’ve made ear-training tutorials and quizzes on vowels and tones precisely because these are the two major areas where vision and proprioception are of least use.
Contrary to a widely held assumption, the sound of speech is as readily visualizable as its articulation; particularly when the all-important time dimension is taken into account. This is truer than ever today; but simplified visualized speech patterns have been around for decades. I recently came across a wonderful picture of phonetician Pierre Delattre taken in 1966 by the great American photographer Ansel Adams: The object held up by Delattre will be recognized by phoneticians as a transparency for a “pattern playback” synthesizer. This technique, pioneered by Franklin S. Cooper at Haskins Labs in the 1950s, aimed to home in on the most significant audible speech patterns by stylizing raw acoustic spectrograms into simple lines and dots that could be read directly by a light-operated synthesizer.
The object held up by Delattre will be recognized by phoneticians as a transparency for a “pattern playback” synthesizer. This technique, pioneered by Franklin S. Cooper at Haskins Labs in the 1950s, aimed to home in on the most significant audible speech patterns by stylizing raw acoustic spectrograms into simple lines and dots that could be read directly by a light-operated synthesizer.
I was curious about the transparency in the Ansel Adams picture, so I rotated and cropped the photo, then boosted the contrast and reversed the black and white, to give this:
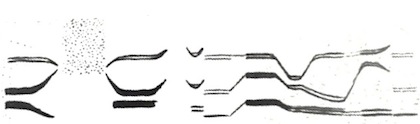 To those with a relatively traditional phonetic background, this acoustic shorthand may be less familiar than head and tongue diagrams. But the basic auditory-acoustic speech patterns are as real now as they ever were, and it doesn’t require a lifetime in a white coat to start deciphering them.
To those with a relatively traditional phonetic background, this acoustic shorthand may be less familiar than head and tongue diagrams. But the basic auditory-acoustic speech patterns are as real now as they ever were, and it doesn’t require a lifetime in a white coat to start deciphering them.
The three main horizontal stripes running through most of the picture are the lowest three resonances or “formants” of sonorant sounds. These formants are interrupted soon after the start by a rectangular scatter of dots, which indicates high-frequency frication; this reaches down to roughly the level of the topmost formant, which suggests that it’s ʃ (if it were higher up, it would be more likely to be s). Prior to this, the lower two formants begin quite close together, then whoosh apart: this suggests an aj-type diphthong, which makes the first syllable likely to be the first person pronoun I.
After the ʃ, the lowest two formants again move towards each other, suggesting an open vowel. There’s then a silent interval, which suggests a voiceless stop; and the slope of the upper two formants on either side of this silent interval suggests that the stop is coronal, t. The utterance is unlikely to begin with anything as vulgar as “I shat”, so it’s probably American English “I shot”.
We can make further interpretations. Sections where the formants are fainter or less solid, as at the midpoint and the end of the image, suggest nasals; the drastic descent of the topmost formant about two-thirds through is a giveaway for ɹ; and so on. Altogether, we can annotate the picture with phonetic symbols as follows:
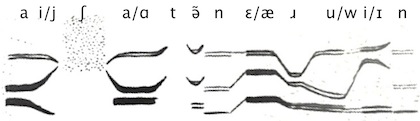 which rather suggests that Delattre was posing for the camera with a famous line by the American poet Longfellow, “I shot an arrow in(to the air)”.
which rather suggests that Delattre was posing for the camera with a famous line by the American poet Longfellow, “I shot an arrow in(to the air)”.
This being the 21st century, there’s an online digital pattern playback, implemented by Keiichi Yasu and Takayuki Arai at Sophia University, Tokyo, to which you can upload jpeg images and have them turned into audible wav files. So, for confirmation, I uploaded my rotated, cropped and negativized bit of the Ansel Adams photo, appropriately scaled, and got this:
A few lines and dots extracted from a 47-year-old photo, scanned by an implementation of 60-year-old technology, and the result, I think, is more intelligible than the robot mouth illustrated above. That certainly appeals to both my visual and my auditory cortices; and not an articulator in sight. (If anyone knows that my description of the picture is wrong, please tell me.)
The speech articulators are important and fascinating. They obviously contribute to phonological variation and change. An understanding of articulation is vital for speech therapy. Debate continues about the role that the motor system may play in speech perception.  Adrian Fourcin himself has devoted much of his career to an articulatory technique, electrolaryngography, which I myself used in linguistic research. When I followed in Abercrombie’s footsteps, teaching phonetics at Edinburgh University, I did my bit to honour local traditions by having an artificial palate made and I found EPG displays great for teaching.
Adrian Fourcin himself has devoted much of his career to an articulatory technique, electrolaryngography, which I myself used in linguistic research. When I followed in Abercrombie’s footsteps, teaching phonetics at Edinburgh University, I did my bit to honour local traditions by having an artificial palate made and I found EPG displays great for teaching.
But I think phonetics can do more to raise awareness of, and encourage sensitivity to, speech as sound – not just as positions and movements of the body. We should acknowledge and celebrate phonetics as the science of hearsay.
(The painting at the top is by Steve Chambers, who holds the brush in his mouth.)
